
機器學習的基礎概念
機器學習是一種人工智能的分支,旨在利用數據來訓練模型,進而預測或分類新的數據。其核心原理是讓電腦自動從數據中獲取知識,而無需明確編程。在機器學習中,預測問題通常可以分為兩大類:分類問題 Classification 和迴歸 Regression 問題。這兩者雖然都是用於預測,但其本質和應用卻有明顯的區別。
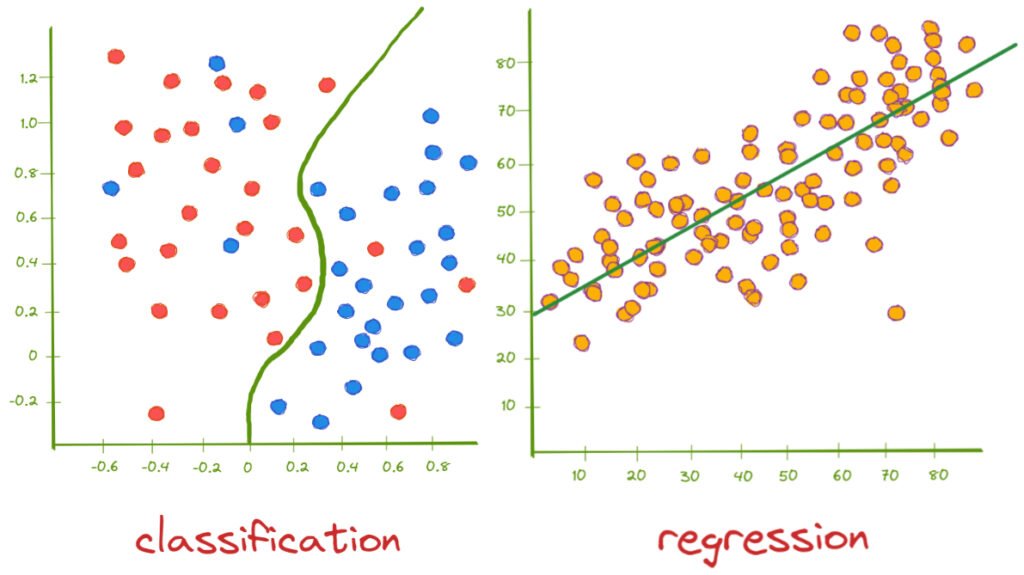
分類問題旨在根據輸入特徵將數據點分配到某一預定的類別中。例如,在賽馬結果的預測中,可將賽馬的結果分為“贏”、“輸”或“位置”、”非位置”等類別。常見的分類算法包括邏輯回歸、決策樹、隨機森林和支持向量機等。這些算法各自有其優勢和局限性,選擇適合的模型通常需要根據具體問題的特點進行判斷。
迴歸問題則是預測一個連續的數值。例如,對於賽馬賽事的結果預測,可能需要預測馬匹在一定距離內的具體名次或時間。迴歸算法中,線性回歸和多項式回歸是最常見的選擇。使用迴歸技巧時,模型應考慮到特徵的多次性和非線性,以提高預測的準確性。
了解分類和迴歸的基本概念及其區別至關重要,因為這將引導研究者在處理不同類型的預測問題時,選擇合適的機器學習技術。這些選擇將直接影響模型的表現和最終結果的可靠性。
賽馬結果的數據特徵
在預測賽馬結果的過程中,了解不同的數據特徵至關重要。這些特徵不僅影響模型的選擇,還對最終預測的準確性有直接影響。首先,馬匹的性能指標包括速度、耐力以及過去比賽的成績等,這些因素能夠提供馬匹在特定賽道上的競爭能力。馬匹參賽的歷史數據,尤其是陣容和對手的實力,同樣對預測結果具有指導意義。
其次,騎師的經驗和技能也是重要的數據特徵。騎師在賽馬中的角色不容小覷,經驗豐富的騎師通常能夠在比賽中作出更快的判斷與策略調整。分析騎師的歷史勝率和與特定馬匹的配合效果,可以進一步提升賽馬結果預測的準確度。
不同的馬匹在不同的賽道條件下表現的差異也是預測時需要考慮的部分。例如,在濕軟的賽道上,某些馬匹可能會表現更好,而另一些馬匹則可能因為適應不良而表現不佳。
由於賽馬結果受到多種因素的影響,這些數據特徵為我們在選擇模型時提供了重要參考。如果選擇分類模型,則更著眼於馬匹的相對表現;而選擇迴歸模型則可幫助我們量化賽馬的預測結果。理解這些特徵的性質和結構,是進一步開展賽馬結果預測的基礎。
分類問題與迴歸問題的比較
在賽馬預測中,應用機器學習的時候,選擇分類問題還是迴歸問題將根據所需的預測結果而定。分類問題是通過將數據點分配到預定的類別中,例如,為每匹馬預測它是否會贏得比賽。這種方法對於需要清晰的輸出結果的情況特別有用,且能利用機器學習算法如支持向量機(SVM)或決策樹進行處理。
相比之下,迴歸問題則關注於預測一個數值輸出,例如,預測一匹馬的完賽時間。在迴歸模型中,理解參數之間的關係是至關重要的,這可以通過線性回歸或隨機森林等技術來實現。當需要獲得更具體的數值預測時,迴歸方法通常是更合適的選擇。
在賽馬預測的具體案例中,使用分類模型會在客觀上無法回答所有問題,例如,當需要預測某匹馬在比賽中排位時,就能更好地使用分類方法,因為賽事的勝者通常只有固定幾個結果(獨贏 W、連贏 Q、位置 P 等)。然而,在需要更精細的時間預測時,則應選擇迴歸模型,因為它能給出更細緻的預測。
選擇分類或迴歸模型還需考慮資料的特性,例如,資料的分佈、標籤的類型及其可用性。因此,了解在何種條件下選擇適當的模型對於準確地進行賽馬結果的預測是相當重要的。這不僅影響預測的準確性,也決定了所需的計算資源和方法的複雜性。
實際應用實測
我們一直都同時有對分類或迴歸模型進行發展及研究,根據我們已有資料,其實兩者都能有效預測賽果。而兩種模型各有特點及好壞,並沒有某一隻模型明顯完勝,不過因為系統運算時間,數據準備成本考慮,我們現時比較多利用分類模型去分析馬匹勝出率。同時我們未來亦會研究同時使用兩種模型作合奏分析,整合結果。